Serverless computing
Serverless computing¶
It was in 2016 at a summit in London that I first heard the “serverless” phrase and I was both confused and intrigued. It was a few talks in when one of the presenters said, “of course there are servers …” Phew that sounds more understandable.
To really appreciate what serverless computing offers, let’s start by defining what a server is. A very common architecture pattern is called the “client-server model”. In the context of a website, the clients are your visitors that connect to your website. Your unique website address, called the domain, allows them to find your website and a (web) server is handling the connections for the different clients. That web server handles requests from the clients - it translate the client requests into client responses. In the past these web servers would have been running permanently, in anticipation of receiving a request from a client. This approach has a few downsides:
Inefficient - the web server is running permanently regardless of whether there are any clients making requests.
Scaling - you need to decide upfront how many clients you expect and then size the web server appropriately. But what happens if there is a sudden spike in traffic that is larger than you web server can handle? It could crash the server.
So what is serverless computing? Of course there are servers, but you do stuff without managing them. By this I mean that you don’t leave the web server running permanently and you don’t size the web server for expected requests. This is handled for you based on demand, i.e. rate of requests.
The major cloud service providers offer serverless computing:
Amazon Web Services - Lambda functions
Google - Cloud functions
Microsoft - Azure functions
The one that I am most familiar with is Amazon Web Services (AWS) Lambda. Let’s look at an AWS provided example that resizes an image in the source bucket and saves the output to the target bucket. The example is from https://docs.aws.amazon.com/lambda/latest/dg/with-s3-example-deployment-pkg.html#with-s3-example-deployment-pkg-python
Here’s the Lambda function in Python 3:
import boto3
import os
import sys
import uuid
from urllib.parse import unquote_plus
from PIL import Image
import PIL.Image
s3_client = boto3.client('s3')
def resize_image(image_path, resized_path):
with Image.open(image_path) as image:
image.thumbnail(tuple(x / 2 for x in image.size))
image.save(resized_path)
def lambda_handler(event, context):
for record in event\['Records'\]:
bucket = record\['s3'\]\['bucket'\]\['name'\]
key = unquote_plus(record\['s3'\]\['object'\]\['key'\])
tmpkey = key.replace('/', '')
download_path = '/tmp/{}{}'.format(uuid.uuid4(), tmpkey)
upload_path = '/tmp/resized-{}'.format(tmpkey)
s3_client.download_file(bucket, key, download_path)
resize_image(download_path, upload_path)
s3_client.upload_file(upload_path, '{}-resized'.format(bucket), key)
Once this Lambda function is created in your AWS Account you can link it to an event. This means that this code will only run when an event occurs, i.e. there is demand so we need a server to handle the request. In the code above:
def lambda_handler(event, context):
This is called the “handler”. It is a Python function definition that takes two inputs: event and context. The event contains details about what made the code run. In this example, the event that this code runs in response to is a new file being created. Specifically, for AWS this means that the Lambda function is running when a new file is added to an S3 bucket. An S3 bucket is just a place to store files and is one example of an event source that can be linked to a Lambda function. However, regardless of cloud provider specifics this serverless approach means that whenever a file is created the following happens:
the event triggers (input)
lambda function starts (server starts)
the image is resized (processing)
a thumbnail is saved (output)
function ends (server stops)
No files added = no servers running, 1 file added = 1 server starts, runs & stops, n files added = n servers start, run & stop. That’s serverless… flexible computing.
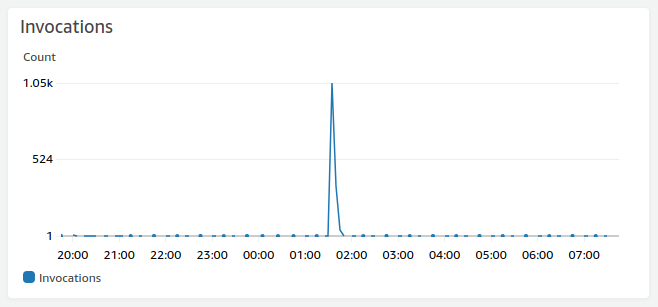
The graph below is from a production system on AWS and shows Lambda function Invocations, the starting of Lambda functions between 20:00 - 07:00. From 20:00 to 01:00 very little is happening, but between 01:00 and 02:00 there is a spike in events, and then from 02:00 very little is happening again. For this system these events were triggered by SEG-Y files being uploaded and then processed to extract metadata from the files.
The advantages of this approach are:
Efficient - we only run servers when they are needed. Within the cloud this translates into a cost saving. Instead of paying to have a server running permanently, you only run servers when they are needed.
Scaling - we don’t need to decide on the size of the server upfront. Instead, servers are stated and stopped depending on the actual demand.
It is a different way of developing applications and it requires a different way of thinking. You need to map out the type of events your application will handle and then connect these with the different function handlers. This approach is called a micoservices architecture. It is becoming an increasingly popular approach to developing applications that run in the cloud.